
大規模な Web サイトは直面する技術的な課題は、主に膨大なユーザー、高並行アクセス、大量のデータによって引き起こされます。どんな単純なビジネスプロセスでも数十ペタバイトのデータを処理し、数億のユーザーに直面する必要があると、煩わしい問題になります。大規模な Web サイトのアーキテクチャは主にこのような問題を解決します。
1.一番シンプルなWebサイトアーキテクチャ
大規模な Web サイトは小規模な Web サイトから進化されることが多いです。構築し始める際にいきなり大規模なWecサイトアーキテクチャを採用するもの(銀行のシステムなど)はありますが、ほとんどの場合は、小規模な Web サイトのアーキテクチャから徐々に進化して成長します。
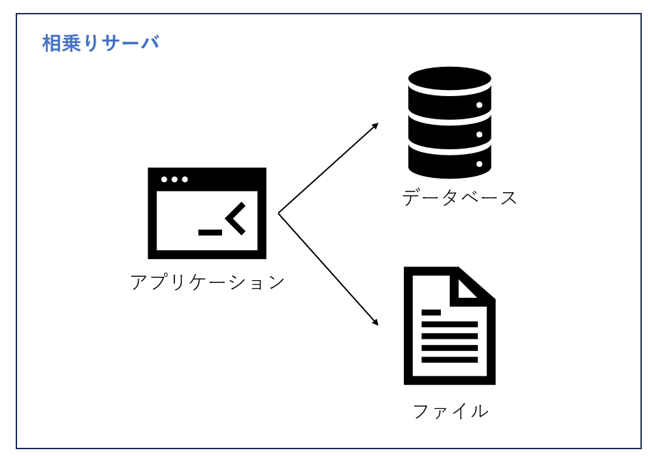
小規模な Web サイトにアクセスする人は少なく、サーバーが 1台を備えば十分でした。この時点の Web サイトのアーキテクチャを図 1.1 のように示します。アプリケーション、データベース、ファイルなどのすべてのリソースが 1 台のサーバー上に配置します。LAMPと聞いたことがあるかもしれませんが、LAMPとは、サーバーのOSは Linux を使用し、アプリケーションは PHP を使用して開発され、その後 Apache にデプロイされ、データベースは MySQL を使用します。このようにさまざまな無料のオープンソース ソフトウェアと低スペックなサーバーを組み合わせることで、簡易にWeb サイトの開発を開始できます。
2.アプリケーションサーバとDBサーバの分離
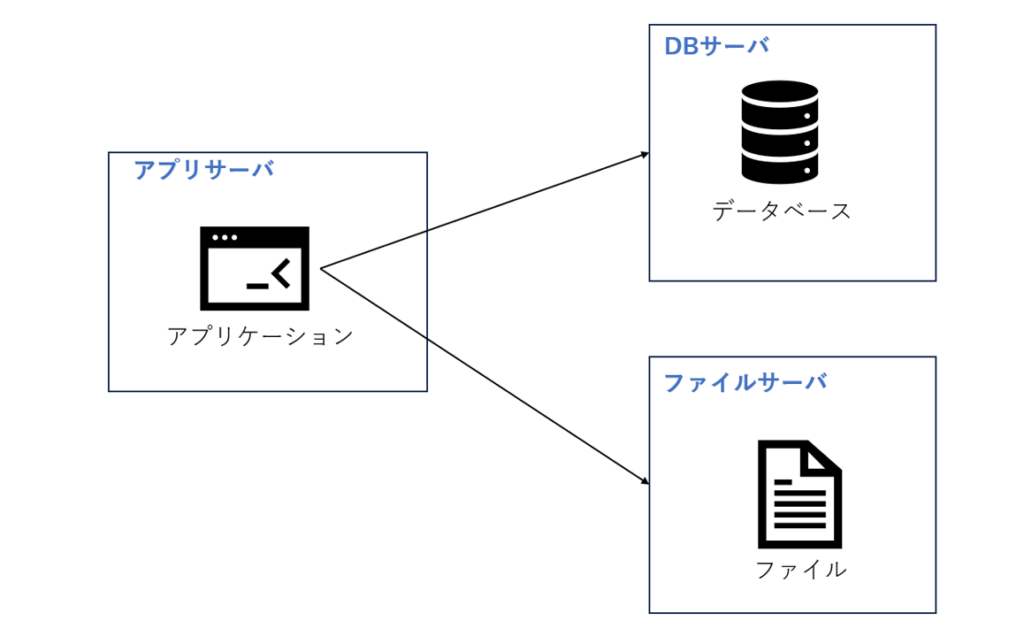
ビジネスの拡大に伴い、1 台のサーバーでは徐々に性能要件を満たせなくなります。アクセスするユーザーが増えるとパフォーマンスが低下したり、データ量が増えるとストレージ容量が不足したりすることがあります。このとき、アプリケーションとデータを分離する必要があります。アプリケーションとデータが分離された後、図 1.2 に示すように、Web サイト全体ではアプリケーションサーバー、ファイルサーバー、データベースサーバーの 3 つのサーバーで構成されます。
これら 3 つのサーバーにはハードウェアリソースの要件が異なります。アプリケーションサーバーは大量のビジネスロジックを処理する必要があるため、より高速で強力な CPU が必要です。データベース サーバーは高速なディスク検索とデータキャッシュを必要とするため、より高速なハードディスクと大容量なメモリが必要です。ファイルサーバーにはユーザーがアップロードした多数のファイルを保存する必要があるため、より大容量なハードディスクが必要になります。
このように、アプリケーションサービスとデータサービスの分離により、異なる特性を持つサーバーが異なる役割を担うようになり、Web サイトの並行処理能力とデータ保存容量が大幅に向上し、ビジネスのさらなる発展をサポートできます 。
3.キャッシュの登場
ユーザー数が徐々に増加するにつれて、Web サイトは別の課題に直面するようになりました。データベースに過度の負荷がかかると、アクセスの遅延が発生し、Web サイト全体のパフォーマンスに影響を及ぼしました。
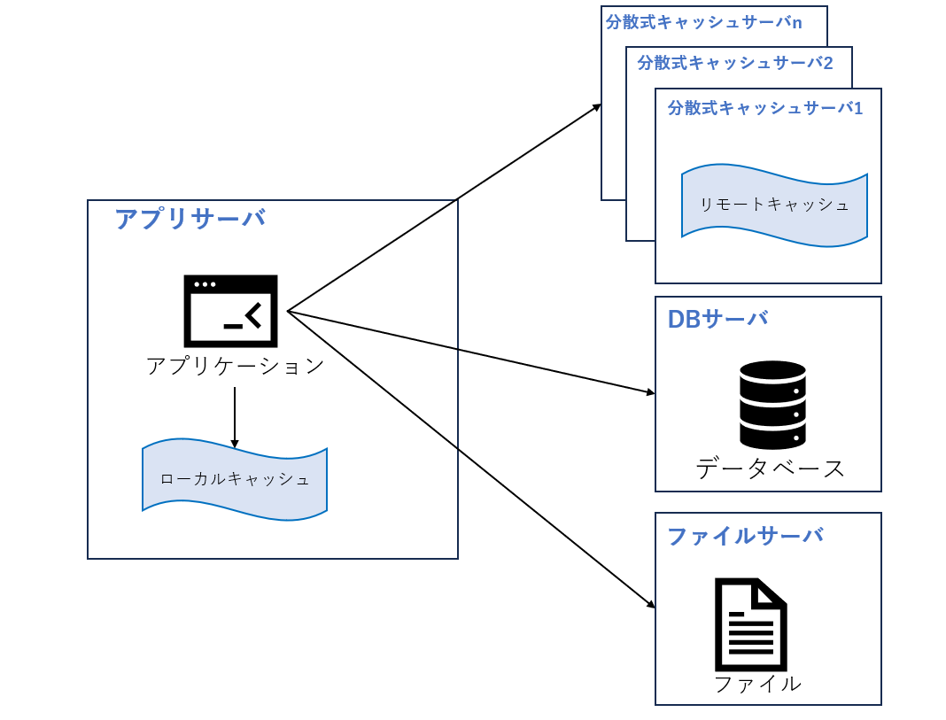
パレードの法則(80:20の法則ともよばれ、1880年代の欧州の経済統計から社会全体の8割の富が2割の富裕層・高額所得者に集中し、残りの2割の富が8割の低所得者に配分されていると着想したことが由来)を聞いたことがあるでしょう。Web サイトアクセスの特徴も同じくパレードの法則に従います。つまり、アクセス量の80%がデータの20%に集中しています。この一部のデータをメモリにキャッシュしておけば、データベースへのアクセス負荷が軽減され、Webサイトのパフォーマンスが向上することを期待できるでしょう。
Web サイトで使用されるキャッシュは2種類あります。アプリケーションサーバーにキャッシュされるローカルキャッシュと、専用の分散キャッシュサーバーにキャッシュされるリモートキャッシュです。ローカルキャッシュのアクセス速度は高速ですが、アプリケーションサーバーのメモリ制限により、キャッシュされるデータの量は制限されます。リモート分散キャッシュでは、図 1.3 に示すように、クラスタを使用して大容量メモリサーバーを専用キャッシュサーバーを構築され、理論的にはメモリ容量に制限されないキャッシュサービスを提供できます。
4.アプリケーションサーバーのクラスタリング
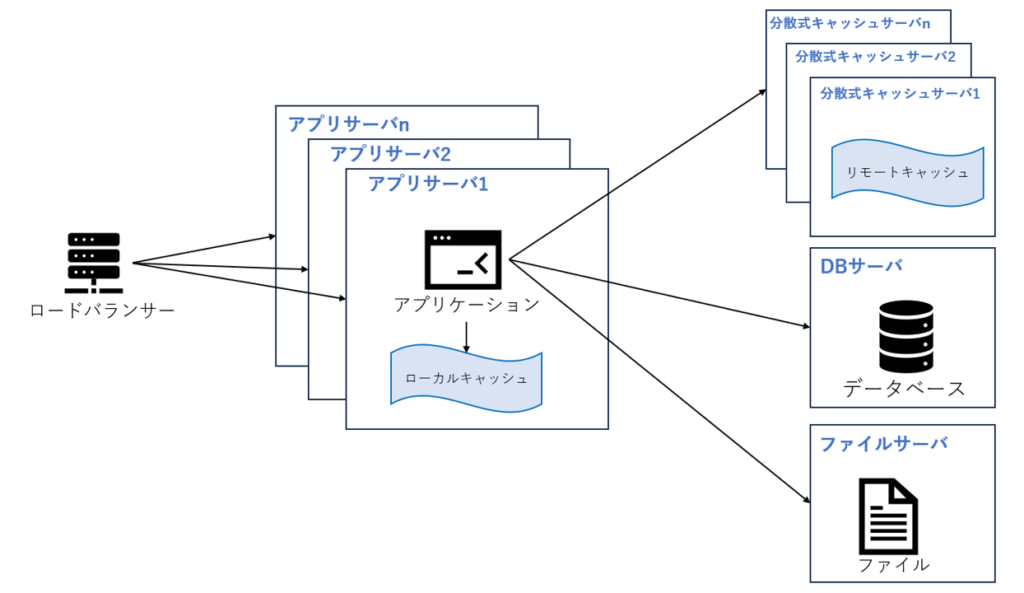
キャッシュを使用すると、データアクセスのプレッシャーは効果的に軽減されますが、Web サイト アクセスのピーク時には、単一のアプリケーションサーバーが処理できるリクエスト接続の数が制限され、アプリケーションサーバーが Web サイト全体のボトルネックになります。
サーバーの処理能力とストレージ容量が不十分な場合は、より強力なサーバーに変更するより、もう一台のサーバーとロードバランザーを追加して、元サーバーのアクセスとストレージの負荷を分散することです。 サーバーの追加によって負荷を低減できる限り、同じ方法でサーバーを追加し続けることによってシステムのパフォーマンスを継続的に向上させることができます。
5. DBのRead/Write分離
キャッシュを使用すると、ほとんどのデータ読み取りはDBを経由せずに完了できますが、一部の読み取り (キャッシュミス、キャッシュの有効期限切れ) と、すべての書き込みがDBへのアクセスが必要となります。DBの多くは、2 つのDB間でマスター/スレーブ関係を構成することにより、あるDBサーバーからのデータ更新を別のサーバーに同期させることができます。 Web サイトは、DBのこの機能を使用してDBの読み取り(Read)と書き込み(Write)の分離を実現し、アプリケーションサーバーがデータを書き込むときにマスターDBにアクセスし、データの更新をスレーブDBに同期します。これにより、アプリケーションがサーバーがデータを読み取るときに、DBからデータを取得できます。
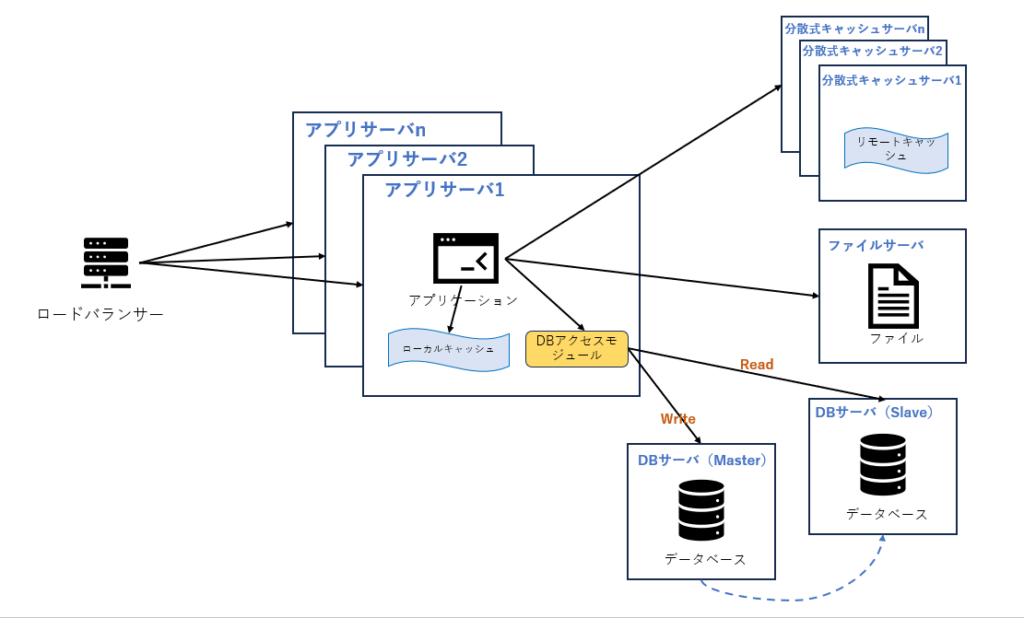
6.リバースプロキシとCDN
ビジネスの国際化になるとともに、ユーザー数はますます増加しており、世界各地の複雑なネットワーク環境により、異なる地域のユーザーがWebサイトにアクセスする速度も大きく異なります。 Web サイトへのアクセスの遅延は、ユーザーを失う大きな要因となります。
ユーザの所在地を考慮して、Web サイトへのアクセスを高速化する手段として、CDNとリバースプロキシを使用することが考えられます。CDN とリバースプロキシの基本原理はどちらもキャッシュです。違いは、CDN がネットワークプロバイダーのDCに配置されるため、ユーザーが Web サイトへアクセスしたときに、最も地理的に近いネットワークプロバイダーのDCからデータを取得できることです。リバースプロキシがWebサイトをホストするDCに配置され、ユーザのリクエストは最初にサーバーがリバースプロキシサーバーユーザーに届き、リクエストしたリソースがリバースプロキシサーバーにキャッシュされている場合、ユーザーに直接返されます。
CDNとリバースプロキシはどちらもWebサイトの外側に配置され、データをできるだけ早くユーザーに返すだけではなく、バックエンドサーバーの負荷軽減にも非常に効果があります。
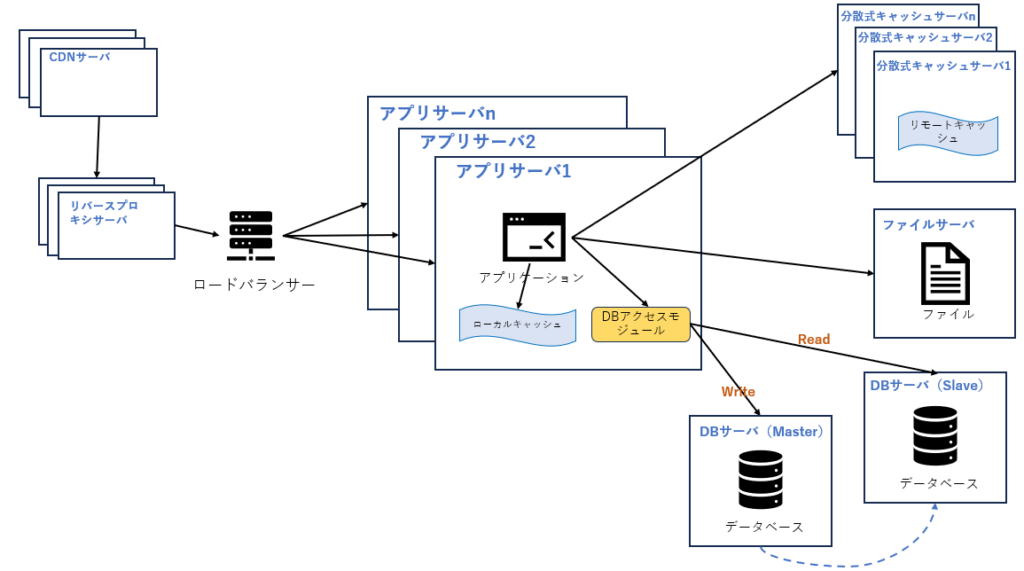
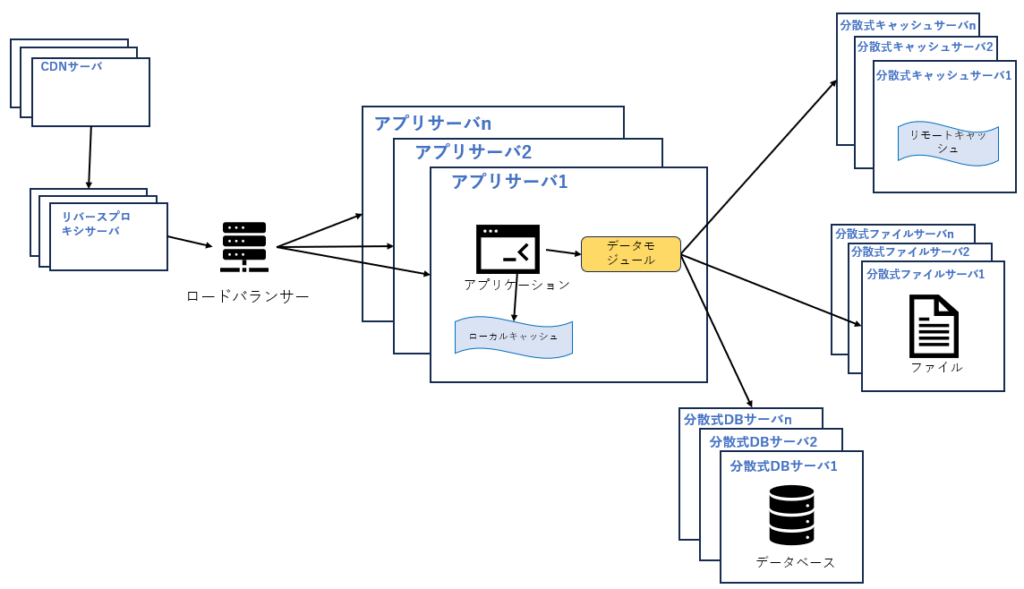
7.分散式DB
DBを読み取りと書き込みを分離した後、1 つのサーバーから 2 つのサーバーに分割されましたが、アクセスがさらに増加すると、Read/Write分離だけでは高並行処理には耐えられません。ファイルシステムにも同じで、図 1.7 に示すように、分散ファイルシステムの使用が必要になります。
ただ、一般的なWebシステムは、分散式DBシステムはWebサイトのデータベース分割の最終手段であり、単一テーブルのデータ規模が非常に大きい場合のみ使用されます。分散式DBシステムを考える前に、業務によりデータを異なるDBに分割することやテーブルのパーテーション分割などを考えるべきでしょう。
8.業務分離
業務複雑化に対応するために、大規模な Web サイトは分割統治手法を採用することが多いです。Webサイト全体の業務をさまざまなパーツに分割します。たとえば、大規模なECサイトでは、ホームページ、ショップ、注文、購入者、販売者などを分割します。さまざまな製品に分かれており、さまざまなビジネスチームに分かれ、各アプリケーションは独立に開発および保守されます。アプリケーションの間は、URL (ホームページ上のナビゲーションリンクはそれぞれ異なるアプリケーションアドレスに指すなど) またはメッセージキューを介して関連付けます。 もちろん、最も一般的な方法は、同じDBにアクセスして関連することです。
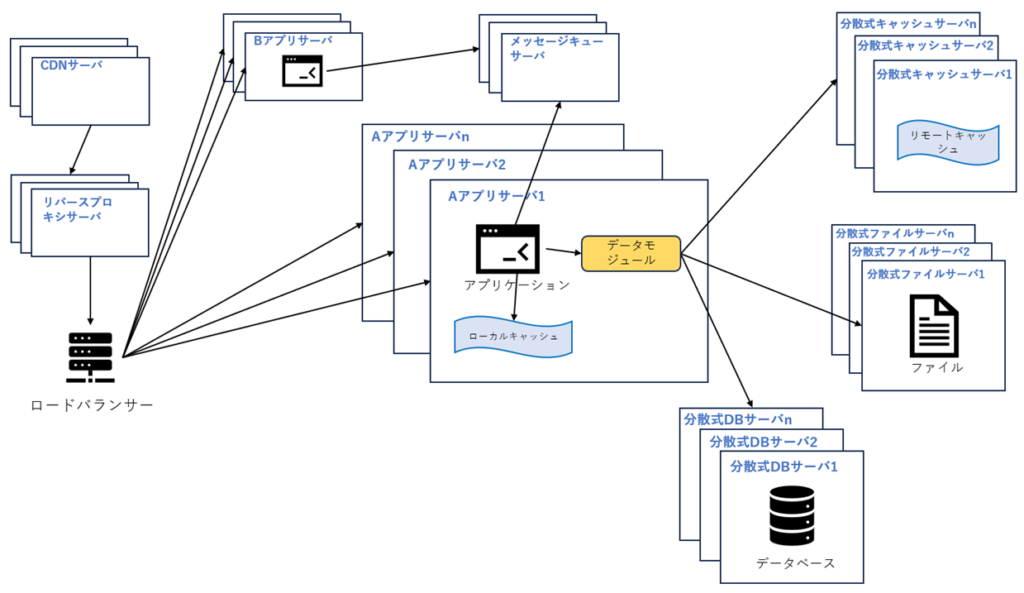
9.分散式業務システム
業務がますます小さく分離され、すべての業務はDBシステムに接続する必要があるなら、DBアクセスリソースが不足になることがあります。例えば各業務中には、ユーザー管理、製品管理など、重複する処理が存在し、これらの重複業務を個別に抽出して配置することができます。これらの再利用可能な業務はDBに接続して共通のサービスを提供し、アプリケーションサーバはこれらの共通のサービスを呼び出すだけで特定の業務を完了できます。
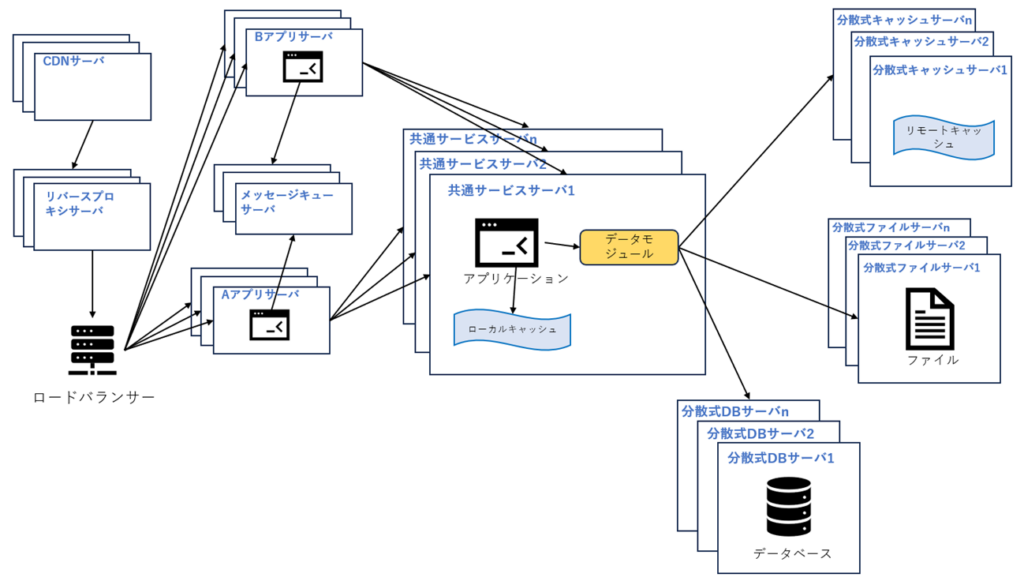
最後に
大規模なWebシステムアーキテクチャはここまで進化すれば、世の中のほとんどの技術問題を解決できるようになるはずです。ただ、無条件にこれらの技術をすべて適用するより、各システムの特徴に合わせていくつかの技術を組み合わせることが望ましい。
今現在、AWSなどのクラウド技術が非常に普及されており、元々システムの拡張には値段、納期、業務成長の予測などを考慮すべき要素が多くありましたが、今は必要に応じてお金を払えば、柔軟にWebアーキテクチャを変更でき、これらの仕組みを簡単に実現できるようになって来ました。
ただ、すべての課題を技術で解決できるわけではなく、業務の改善なども考えないといけません。例として、中国は鉄道の予約システムをリリースされた直後の2012〜2014年に、春節の帰省ラッシュ時に予約が殺到し、毎年定例のようにシステムが長時間にダウンとなる大きな事故がありました。当システムは一日最大アクセス量は数百億(2024年は800億/日を超えています)で、技術的にこの量の並行処理は技術的な手段で解決するのはほぼ不可能となり、業務的な見直し(毎日の0時から集中販売開始から時間ごとに販売開始するようになったなど)により大きく改善できた話があります。
確かに、業務的に高並行を平滑化させ、技術的に高並行処理を対応するのは一番のアプローチかもしれませんね。


コメント